
-
- Downloads
update readme
Showing
- .gitignore 3 additions, 1 deletion.gitignore
- README.md 112 additions, 1 deletionREADME.md
- doc/back.png 0 additions, 0 deletionsdoc/back.png
- doc/dataset_example.png 0 additions, 0 deletionsdoc/dataset_example.png
- doc/epoch1.PNG 0 additions, 0 deletionsdoc/epoch1.PNG
- doc/epoch10.PNG 0 additions, 0 deletionsdoc/epoch10.PNG
- doc/epoch30.PNG 0 additions, 0 deletionsdoc/epoch30.PNG
- doc/epoch5.PNG 0 additions, 0 deletionsdoc/epoch5.PNG
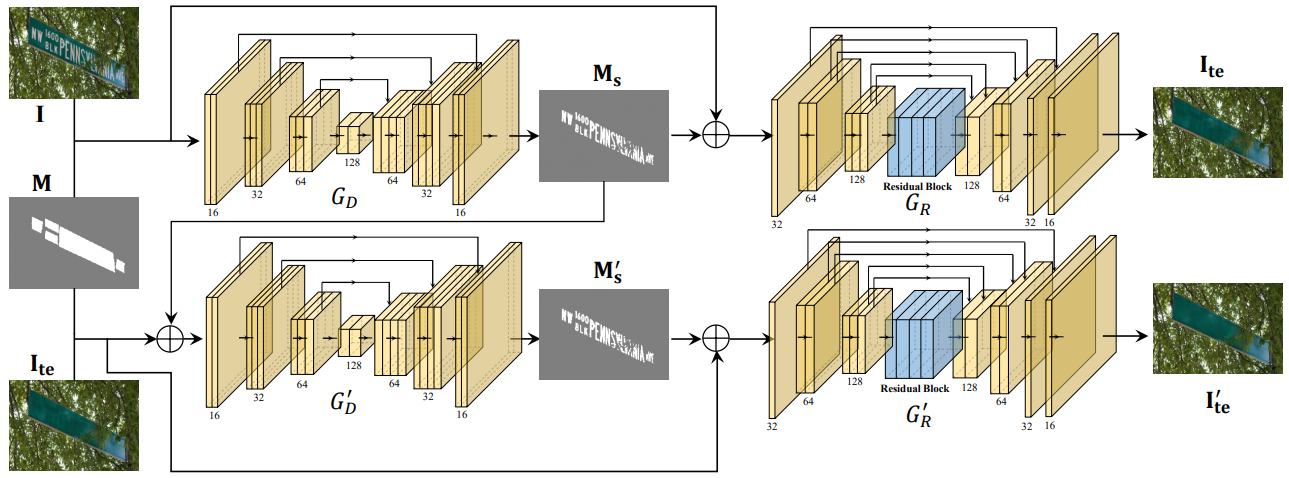
- doc/model.png 0 additions, 0 deletionsdoc/model.png
- doc/text.png 0 additions, 0 deletionsdoc/text.png
- requirements.txt 4 additions, 0 deletionsrequirements.txt
- results/show/Thumbs.db 0 additions, 0 deletionsresults/show/Thumbs.db
doc/back.png
0 → 100644
{kind=link}

14.2 KiB
doc/dataset_example.png
0 → 100644
{kind=link}

222 KiB
doc/epoch1.PNG
0 → 100644
{kind=link}

124 KiB
doc/epoch10.PNG
0 → 100644
{kind=link}

151 KiB
doc/epoch30.PNG
0 → 100644
{kind=link}

117 KiB
doc/epoch5.PNG
0 → 100644
{kind=link}

147 KiB
doc/model.png
0 → 100644
{kind=link}
280 KiB
doc/text.png
0 → 100644
{kind=link}

1.13 KiB
requirements.txt
0 → 100644
| opencv-python | ||
| matplotlib | ||
| numpy | ||
| tqdm | ||
| \ No newline at end of file |
results/show/Thumbs.db
0 → 100644
File added